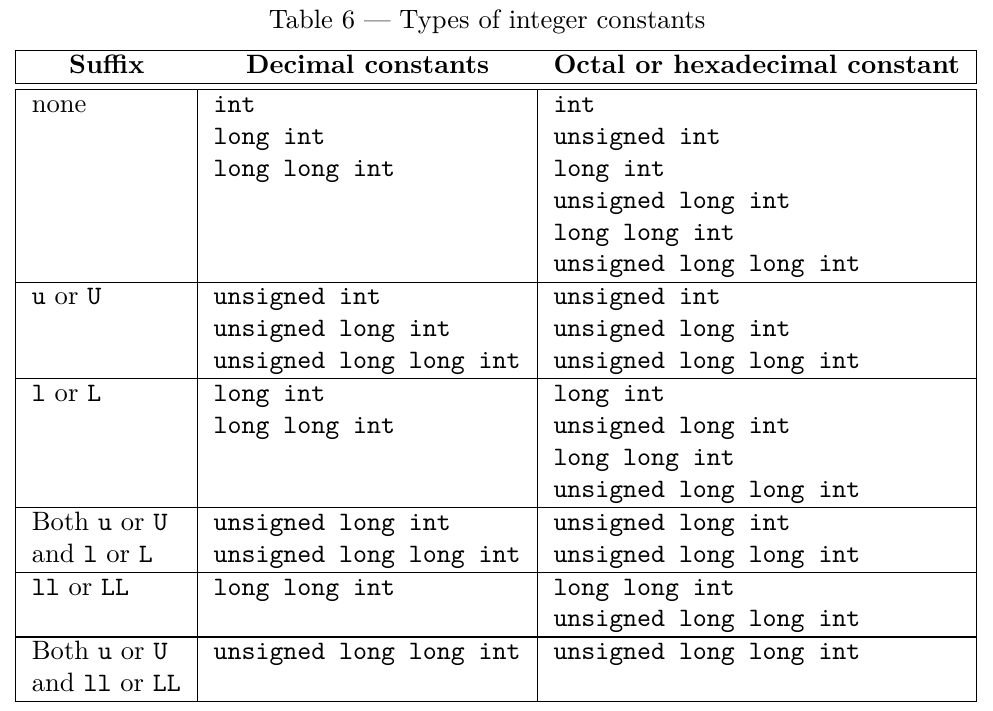
In C++, what exactly is -1u?
It doesn’t seem like it should be difficult to answer — it’s only three characters: –, 1, and u. And, knowing a little bit about C++, it seems like that’ll be (-1) negative one with that u making ((-1)u) an unsigned int. Right?
To be more specific, on an architecture where int is a 32 bit type, and negative numbers are represented using two’s complement (i.e. just about all of them), negative one has the binary value 11111111111111111111111111111111. And converting that to unsigned int should … still be those same thirty two ones. Shouldn’t it?
I can test that hypothesis! Here’s a program that will answer the question once and for all:
#include <stdio.h>
#include <type_traits>
int main()
{
static_assert(std::is_unsigned<decltype(-1u)>::value,
"actually not unsigned");
printf("-1u is %zu bytes, with the value %#08x\n ",
sizeof -1u, -1u);
}
Compile and run it like this:
g++ -std=c++11 minus_one_u.cpp -o minus_one_u && minus_one_u
If I do that, I see the following output:
-1u is 4 bytes, with the value 0xffffffff
I’m using -std=c++11 to be able to use std::is_unsigned, decltype and static_assert which combine to assure me that (-1u) is actually unsigned as the program wouldn’t have compiled if that wasn’t the case. And the output shows the result I had hoped for: it’s a four byte value, containing 0xffffffff (which is the same as that string of thirty two ones I was looking for).
I have now proven that -1u means “convert -1 to an unsigned int.” Yay me!
Not so much.
It just so happened that I was reading about integer literals in a recent draft of the ISO C++ standard. Here’s the part of the standard that describes the format of decimal integer literals:
2.14.2 Integer literals
1 An integer literal is a sequence of digits that has no period or exponent part, with optional separating single quotes that are ignored when determining its value. An integer literal may have a prefix that specifies its base and a suffix that specifies its type. The lexically first digit of the sequence of digits is the most significant. A decimal integer literal (base ten) begins with a digit other than 0 and consists of a sequence of decimal digits.
Can you see where it describes negative integer literals?
I can’t see where it describes negative integer literals.
Oh.
I though -1u was ((-1)u). I was wrong. Integer literals do not work that way.
Obviously -1u didn’t just stop producing an unsigned int with the value 0xffffffff (the program proved it!!1), but the reason it has that value is not the reason I thought.
So, what is -1u?
The standard says that 1u is an integer literal. So now I need to work out exactly what that – is doing. What does it mean to negate 1u? Back to the standard I go.
5.3.1 Unary operators
8 The operand of the unary – operator shall have arithmetic or unscoped enumeration type and the result is the negation of its operand. Integral promotion is performed on integral or enumeration operands. The negative of an unsigned quantity is computed by subtracting its value from 2n, where n is the number of bits in the promoted operand. The type of the result is the type of the promoted operand.
I feel like I’m getting closer to some real answers.
So there’s a numerical operation to apply to this thing. But first, this:
Integral promotion is performed on integral or enumeration operands.
Believe me when I tell you that this section changes nothing and you should skip it.
I have an integral operand (1u), so integral promotion must be performed. Here is the part of the standard that deals with that:
4.5 Integral promotions
1 A prvalue of an integer type other than bool, char16_t, char32_t, or wchar_t whose integer conversion rank (4.13) is less than the rank of int can be converted to a prvalue of type int if int can represent all the values of the source type; otherwise, the source prvalue can be converted to a prvalue of type unsigned int.
I’m going to cut a corner here: integer literals are prvalues, but I couldn’t find a place in the standard that explicitly declares this to be the case. It does seem pretty clear from 3.10 that they can’t be anything else. This page gives a good rundown on C++ value categories, and does state that integer literals are prvalues, so let’s go with that.
If 1u is a prvalue, and its type is unsigned int, I can collapse the standard text a little:
4.5 Integral promotions (prvalue edition)
A value of an integer type whose integer conversion rank (4.13) is less than the rank of int …
and I’m going to stop right there. Conversion rank what now? To 4.13!
4.13 Integer conversion rank
1 Every integer type has an integer conversion rank defined as follows:
Then a list of ten different rules, including this one:
— The rank of any unsigned integer type shall equal the rank of the corresponding signed integer type.
Without knowing more about conversion ranks, this rule gives me enough information to determine what 4.5 means for unsigned int values: unsigned int has the same rank as int. So I can rewrite 4.5 one more time like this:
4.5 Integral promotions (unsigned int edition)
1 [This space intentionally left blank]
Integral promotion of an unsigned int value doesn’t change a thing.
Where was I?
Now I can rewrite 5.3.1 with the knowledge that 1u requires no integral promotion:
5.3.1 Unary operators (unsigned int operand edition)
8 The [result of] the unary – operator … is the negation of its operand. The negative of an unsigned quantity is computed by subtracting its value from 2n, where n is the number of bits in the promoted operand. The type of the result is the type of the operand.
And, at long last, I get to do the negating. For an unsigned value that means:
[subtract] its value from 2n, where n is the number of bits in the promoted operand.
My unsigned int has 32 bits, so that would be 232 – 1. Which in hexadecimal looks something like this:
0x100000000
- 0x000000001
0x0ffffffff
But that leading zero I’ve left on the result goes away because
The type of the result is the type of the (promoted) operand.
And I am now certain that I know how -1u becomes an unsigned int with the value 0xffffffff. In fact, it’s not even dependent on having a platform that uses two’s complement — nothing in the conversion relies on that.
But… when could this possibly ever matter?
For -1u? I don’t see this ever causing actual problems. There are situations that arise from the way that C++ integer literals are defined that can cause surprises (i.e. bugs) for the unsuspecting programmer.
There is a particular case described in the documentation for Visual C++ compiler warning C4146, but I think the rationale for that warning is wrong (or, at least, imprecise), but not because of something I’ve covered in this article. As I’ve already written far too many words about these three characters, I’ll keep that discussion for some time in the future.