Update:This chart has been updated and I’ve added charts for C++11 Concurrency, C++14, and C++17 here.
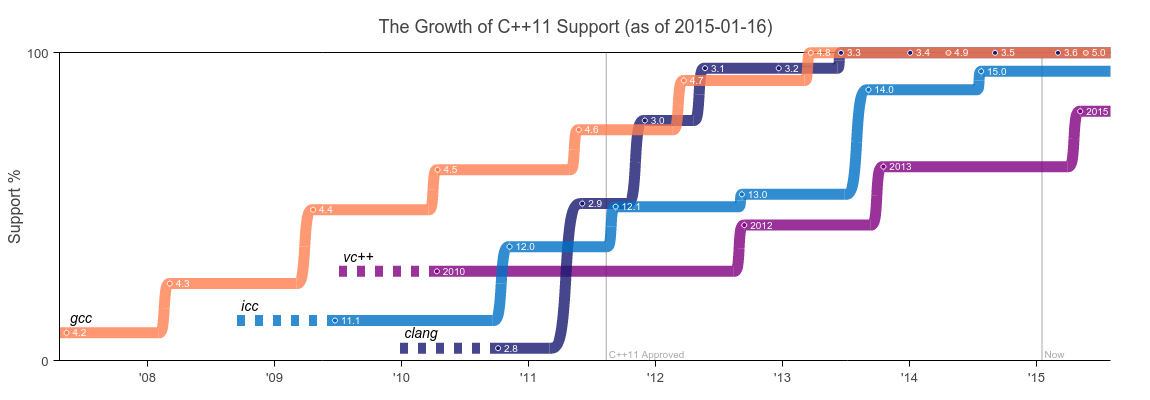
A few days ago, Christophe Riccio tweeted a link to a pdf that shows the level of support for “Modern C++” standards in four C++ compilers: Visual C++, GCC, Clang, and ICC.
One of the things I wanted to see was not just how support had advanced between versions of each compiler, but how compilers had changed relative to one another over time. I extracted the numbers for C++11 from Christophe’s document, found the release dates for each compiler, and created a chart that puts it all together.
It’s interesting to see how far behind Clang starts in comparison to the others, and that it ends up in a close dance with GCC on the way to full C++11 support. It also highlights how disappointing VC++ has been in terms of language feature advancement — particularly when VS2010 was ahead of Clang and ICC for C++11 features.
Creating the chart also served as an opportunity to play around with data visualization using Bokeh. As such, you can click on the chart above and you’ll see a version that you can zoom, pan, and resize (which is only a small part of what Bokeh offers). I intend to write about my experiences with Bokeh at a later date.
Release dates for each compiler were taken from the following pages:
CppCon 2014 talk by Chandler Carruth:
“Efficiency with Algorithms, Performance with Data Structure”
It starts slow, but there’s plenty of good things in this one:
Don’t use linked lists [0]
std::map is terrible
Computers are made of memory hierarchies [1]
[If you’re going to use it, ] know how the standard library works [2]
std::unordered_map has a ridiculously long name and it isn’t a good hash map
[0] The thing about linked lists is that they’re at their worst when there is no spatial locality between the elements. Because of the way that std::list allocates elements, this will almost always be the case.
Linked lists can be useful for gathering data, but they’re expensive to traverse and modify. If you need to traverse the list more than once, consider using the first traversal to repack the list into a vector.
[1] The presentation does give some insight into the relative cost of cached memory accesses, and it would be remiss of me to not link to Tony Albrecht’s interactive cache performance visualizer. And std::vector is recommended over std::list for the spatial benefits (elements known to be near other elements, which is good). But the value of ordered accesses was overlooked in the presentation.
Put your data in a vector and process it in order from one end to the other. Any decent CPU will detect the ordered access and prefetch the data into the cache for you, and less time will be spent waiting for that data. It’s like magic.
[2] The presentation included two very specific examples regarding the inner workings of the standard library, one for std::vector, and one for std::unordered_list. It is right and good that you understand the workings of any library that you are using, but there were more general principles that were imho overlooked:
For std::vector and std::list (and not exclusive to them): JIT memory allocation is terrible — use what you know about the problem to minimize and manage memory allocations. To quote from Andreas Fredrikssons’ fine rant (which you should read): Never make memory management decisions at the lowest level of a system.
Always explicitly keep a copy of intermediate results that are used more than once. Don’t trust the compiler to optimize for you — more to the point, understand why compilers legitimately can’t optimize away your lazy copypasta. (Mike Acton’s CppCon keynote has some material that covers this)
I recently watched the CppCon 2014 talk by John “JT” Thomas:
“Embarcadero Case Study: Bringing CLANG/LLVM to Windows”
The presentation brought a few things to mind about which I have opinions :)
Don’t let upstream get away from you
If you’re going to build upon a codebase that you don’t own, a codebase that others are adding enhancements to, where those enhancements are visible to your customers and are available to your competitors — why would you do anything but keep as close as possible to that upstream development?
“JT” argues in favor of following upstream more closely than they did. I’ve read [it seems like] many articles that insist that the only sane way to do Linux kernel driver development is the same — at least if you ever want your changes to be merged, or you want them to be maintainable into the future.
Playing catch-up is hard work, not made easier when upstream is highly active (as is the case for LLVM/clang or the Linux kernel). Investing developer time into regularly integrating changes from upstream is far more palatable than the epic upheaval that comes from chasing major releases.
It seems like regularly integrating has some tangible benefits:
You get the new features as soon as possible. (Also, you get the new bugs. This is software development.)
More manageable schedules. Regular integration will be far more predictable in terms of the time it takes to adapt your branch. There is a limit to how much change can happen upstream at one time. Smaller, regular changes are more predictable, and less likely to cause huge timesinks for programmers i.e. it’s better from a project management perspective.
Reveal conflicts closer their source — it’s better to fix code recently written than having to rewrite it months later.
And, if you’re doing it from the outset, it means the team can become comfortable with that workflow, and develop the skills and judgement to maintain it. Trying to learn those skills after working in a stable branch/dreamworld is only going to increase the friction when the change takes place.
Consider the full cost of contractors
Don’t pay someone outside of your team to develop intimate knowledge about your systems — you’ll need to pay for it again when members of the team have to learn how to maintain and extend those systems at some point in the future.
This is partial text from a slide at around 50:50 in the presentation:
Initial contract work led to slow integration
Core compiler team took time out to integrate and get up to speed
This type of initial work would have been best done in house or with much closer interaction
Using contractors to add features to your software comes at a cost to the team: no one on the team will know what the contractor learned while completing the task — not the way that the contractor does. No one will have full insight into why decisions were made the way that they were. If you want your team to be able to support the code after the contractor is finished, you’ll need to set aside more time to develop familiarity.
In many cases, it’s better to kill two birds with one stone: let someone familiar with your codebase do the work of learning about the new area. You’ll keep the expert knowledge on the team, and any newly written code will have a better chance of fitting in with existing standards and practices of the codebase.
If it’s something that you expect to be using and maintaining into the future, keep it in-house. Or expect to keep paying the contractor, and plan for the cost of poorly integrated code.
A busy few weeks. A visit from an old friend, a server migration (which isn’t yet complete), and life.
Migrating a bunch of mailman lists to google groups has gone fairly smoothly. The MailMan Archive Migration tools turned out to be very useful — the reposted messages appear with the time they were reposted and the order seems to be a bit mysterious, but everything’s there to the satisfaction of all the interested parties. A more frustrating limitation when migrating lists is that users can be added ten at a time to a maximum of 100 per day. Hopefully I only need two days worth.
The rest of the server migration falls under the headings of domains and databases. Nothing particularly exotic, mostly tedious.
The last two weeks in code…
Opportunistic extraction — wrote a little bit of perl to make the most of some readily available well-structured data and provide easily readable update information in a particular script. The results are pretty good — and it will probably break as a side effect of some other change at an indeterminate time in the future.
Related thought: dependency tracking. How can we better track reverse dependencies? Not only are unknown consumers of code & data a common source of bugs, that changing some code might break something else becomes a cause for code stagnation. We can do better.
Breaking everyone’s everything — migrating a lot of code to a new shiny settings management system. Worth the effort, but a lot of time spent diagnosing complex interactions between build configurations, target macros, and my own mistakes while working with a third-party’s shiny new code. Related: adding diagnostics. Also related: removing silly old hacks. Both of these can be quite satisfying.
Fixing my own breakage — turns out that bugs added in an unrelated branch can languish a long time before they get noticed. Better testing habits seem desirable. Also, being a less terrible programmer.
Technical debt — hacks put in place to get an app reliably demoable may not be suitable for use outside the demo. I demoed a thing — it went well (really well). But then I needed days to clean up the frenzy of code hacks, and even then I ended up with bugs that would bite a week later. Probably a lesson there.
Using these as the subject matter, construct 6 really good puns.
Answers:
After receiving a range of questions from different sources, I was unsure which to answer first — I was stack as to where to begin. And so because this was the last question that I received, it became the first that I answered.
—
Don’t get me wrong — I did appreciate the question. The capacity of my gratitude is, theoretically, unbounded. Thanqueue.
—
We have a cuckoo aviary. I keyp a record of each birth in a hatch table.
—
I noticed that I was leaning to one side. I spoke to a physician about it — he told me I was overweight because I was eating too much bread. My list, it seems, is linked to my dough-belly.
—
On a school trip to a pickle factory, my daughter went missing. I was able to climb the brinery search tree and spot her, though it took longer than I had hoped due to my poor balance.
—
While out walking, I deflected a cyclist’s gaffe, knocking him aside as he rode the wrong way down a one-way street. I looked down my nose at him and gave a topological snort to help him on his way.
The reader may decide whether the answers satisfy the requirements of the question.
It took far too long, but I finally realized that when trying to filter categories from the front page, the index.php that the howtos are referring to is the index.php of the template.
Coding today: found some bugs, fixed some of what I found.
One was a genuine stack overflow — the stack pointer was being decremented by more than the entire size of the thread’s stack in the prologue to a particular function, landing in the land of unmapped pages. The fix was simple (once I found the right stack size to adjust), but the cause wasn’t clearly obvious to me. In hindsight, I was debugging in the wrong direction.
The way it happened: something like this was causing the crash half way through the function:
mov qword ptr [rbp-4040h], rdx
I was fixated on what that rdx was to try to work out why this was happening (completely overlooking the presence of rbp and the roundish nature of the constant). A quick trip to the ABI docs led me to believe that rdx was a function argument that was entirely unused in the function. And that left me second-guessing my own interpretation — what did this mean? What critical purpose does this instruction serve?
Actually, none.
The data was being pushed to the stack because that’s the sort of code that compilers generate (i.e. the odd instruction that serves no apparent purpose).
It did all become extremely obvious after rebuilding the function in question without optimizations and seeing a cluster of mov [rbp 0x40??], all resolving to unmapped memory.
Other issues: NULL member vars where they were not expected (which was fixed by not me), mismatched sizes for a variable being passed through an opaque interface, a warning at shutdown where some objects were not being explicitly destroyed, more adjustments to filesystem code so that things compile and function [more] correctly on all the necessary platforms.
One rather not-awesome bug that remains unfixed is some serialized game data with alignment problems. A bunch of structs changed size recently — it looks like at least one of them needs some realignment counselling. (Finding the hash of a string inside a counter fills me with delight*)
I spent some time debugging problems with our navmesh generator (aka navbuilder). Right now, we uncritically pass geometry to recast even if the vertical range of the geo is beyond what recast’s heightfield (as configured by us) can represent. Exceeding that range causes problems – for whatever reason, all generated navmesh ends up being pushed to a low extreme, and then the tools that consume the generated navmesh choke. It’s something that needs to be fixed, but there are more pressing issues right now. And there are workarounds :\
Completed (“completed”) migration of this blog to the new webhost — DNS has been redirected, and there’s a non-zero chance that someone apart from me can see this. Next: all the other sites & services still on the old host… :\
(I find it interesting how much working on a host with a low ping vs one on another continent makes it genuinely appealing for me to get back to the command line on these boxes.)
Coding today, I was able to port filesystem wrappers & our archive filesystem to a new platform. And it worked second time (not counting the compile & link errors and code shuffling necessary to find the things that needed to be un-if-zeroed/implemented/if-zeroed). The biggest change was due to not using overlapped IO for the archive FS on the new platform — all archive IO is already async to the main thread, but there was support for multiple in-flight operations that can improve overall throughput. The first cut lacks that support for overlapped IO — and the bug I introduced was because I missed the explicit seek necessary to perform accurate reads from archives. Instead, random reads were being serviced sequentially from the start of the archive file. Easy enough to fix, and initial testing indicates that it’s Fast Enough. Until tomorrow, at least.
Found a bug that I’d added to some other code: I had added a new codepath, but failed to set some state in both the new and old codepaths. Fix applied was to hoist the setting of said state above the branch, but in hindsight I think the variable in question is able to be removed and the consumer of said state made a little smarter…
Found some other code that turned out to be not trivially portable, that was also not worth porting. Fix was the delete key.
Spent some time this morning helping to diagnose a weird compilation failure related to linker segment flags not matching in some wonderfully obscure circumstances. XP gained: decoding link flags from the “PE and COFF Specification” http://msdn.microsoft.com/en-us/windows/hardware/gg463119.aspx
Watched Jonathan Blow’s programming language talk (see other post)
Jonathan Blow demoing a programming language for games. Plenty of interesting things.
Thoughts…
compile-time code execution — being able to do codegen at compile time seems potentially really useful (speaking from recent experience wrangling code generators and keeping generated code in sync with the human generated stuff)
scalability — there are things about compilation, dependency management, and the arbitrary compile-time code execution that seem … risky when used in the context of large, complex projects
control — will this language provide the level of control that a low level engine programmer needs/desires? Alignments of all the things, segments, SIMD/intrinsics, inline asm, _penter hooks etc. (to name a few things that I can think of from the past week) It doesn’t need to, but I wonder about these things.
Earlier this year, I compiled a list of game studios that had maintained continuous operation for more than twenty years because … well because it interested me. Here’s an updated list for 2014 (a couple of days early).
Studio history fascinates me — how studios have developed over time, studios with long lists of popular games, or short lists of unpopular ones. Revealing names that have been influential to me as a young gamer and game developer, and places that friends and acquaintances have worked at. Seeing video game development as an industry with significant history (good and bad), and to learn about how we got to where we are. What has endured, and what has not.
There’s a lot that can be learned. Here are links to some of it.
(These lists are assuredly incomplete — let me know what I’ve missed)
SN Systems has been making tools for game development since 1988. RAD Game Tools has also been around since 1988.
Updates: Added Egosoft thanks to @RonPieket
Added Guerrilla Cambridge, SCE Bend Studio, and SCE London Studio thanks to @TobiasBerghoff
Added Ubisoft Paris thanks to @wsmind
Added Atod AB thanks to @martinlindell
Added EA Phenomic (closed 2013) thanks to @JanDavidHassel
Added Ubisoft Bucharest thanks to @kitzkar
Added Traveller’s Tales thanks to @DanOppenheim Added Llamasoft thanks to @RonPieket Added Frontier Developments thanks to @tom_forsyth
Added Visual Concepts thanks to Lisa Buechele
Added Image Space Incorporated thanks to Gjon Camaj
Added WayForward Technologies after meeting the CEO John Beck at the USC Fall Demo Day :)
[I plan to write a more complete article with pictures at a later date. For now, this.]
I have peculiar taste in coffee, at least when compared to what’s readily available in the local area. I have thus far failed to find a reliable, affordable source of roasted coffee beans that suit my particular predilection. My wife suggested I try roasting my own.
I’ve known a few people that have roasted coffee beans for their own use with excellent results — and significant investment of time and effort. I had been unwilling to enter this rabbit hole. After continued (albeit mild) frustration and some encouragement, I’m diving in.
Based on the experience (and success) of some good friends, I’ve opted for a bread machine + heat gun roasting configuration (aka “Corretto”): it provides a good ratio of control and consistency to cost. Additionally, I’ve taken inspiration from Andrew Tridgell’s linux.conf.au talk from a couple of years ago when preparing my setup.
I have, thus far, acquired the following:
Roasting basics
Bread machine — 2lb model, found at a local thrift store.
A surface upon which to set these things — Some timber and screws to make a rough table.
Still to arrive
Multimeter — Includes thermocouple, USB connectivity.
Progress
Putting it all together has gone reasonably smoothly — the mic stand holds the heat gun (ordering online means it’s hard to judge the strength of the clip, gooseneck or weight of the heatgun before purchase…), I managed to build a sufficiently sturdy table of adequate dimensions, the cooling assembly works as well as I could have hoped (I really wasn’t sure what I was looking for on this front — I purchased pieces that I thought I could combine in an adequate fashion, and got lucky)
The bread machine has an adequate knead setting that keeps the beans moving, though it does pause and change pace and direction during a roast. I was hoping that I could mod it to run the motor continuously and it seems like that might not be too difficult.
This particular bread machine has a temperature sensor that shuts the whole thing down should it get too hot, which happened during my first roast. I relocated the sensor to a more temperate part of the machine.
For the more frugal aspiring coffee roaster, many of these items could have been purchased more cheaply at yard sales or similar. I was motivated by cost and convenience — driving all over the city to save a few $ didn’t strike me as being worthwhile. YMMV. And though we have a vacuum cleaner, I was reluctant to risk heat damage to it.
The multimeter appears to be the same model used by tridge in his setup (and by others if the results of googling the model number are anything to go by), so I’m hoping that it won’t be too much work to get it working with pyRoast and visualize/log roasts. I’ll be able to find out more when it eventually arrives.
The other side of tridge’s setup is the auto-power control and I’m hopeful that the heatgun I’ve chosen will avoid the need for the full custom power control device — I’d like to be able to have pyRoast control the heatgun directly to vary the temperature during the roast. This bit is more of a personal stretch goal.
I’ve successfully roasted beans with this setup but without any kind of temperature feedback, the results seem pretty random. That said, having freshly roasted beans from my own roaster has already been a wonderful thing!
{kind=link}