Navigation mesh encodes where in the game world an agent can stand, and where it can go. (here “agent” means bot, actor, enemy, NPC, etc)
At runtime, the main thing navigation mesh is used for is to find paths between points using an algorithm like A*: https://en.wikipedia.org/wiki/A*_search_algorithm
In Insomniac’s engine, navigation mesh is made of triangles. Triangle edge midpoints define a connected graph for pathfinding purposes.
In addition to triangles, we have off-mesh links (“Custom Nav Clues” in Insomniac parlance) that describe movement that isn’t across the ground. These are used to represent any kind of off-mesh connection – could be jumping over a car or railing, climbing up to a rooftop, climbing down a ladder, etc. Exactly what it means for a particular type of bot is handled by clue markup and game code.
These links are placed by artists and designers in the game environment, and included in prefabs for commonly used bot-traversable objects in the world, like railings and cars.
Navigation mesh makes a certain operations much, much simpler than it would be if done by trying to reason about render or physics geometry.
Our game work is made up of a lot of small objects, which are each typically made from many triangles.
Using render or physics geometry to answer the question “can this bot stand here” hundreds of times every frame is not scalable. (Sunset Overdrive had 33ms frames. That’s not a lot of time.)
It’s much faster to ask: is there navigation mesh where this bot is
Navigation mesh is relatively sparse and simple, so the question can be answered quickly. We pre-compute bounding volumes for navmesh, to make answering that question even faster, and if a bot was standing on navmesh last frame, it’s even less work to reason about where they are this frame.
In addition to path-finding, navmesh can be useful to quickly and safely limit movement in a single direction. We sweep lines across navmesh to find boundaries to clamp bot movement. For example, a bot animating through a somersault will have its movement through the world clamped to the edge of navmesh, rather than rolling off into who-knows-what.
(If you’re making a game where you want bots to be able to freely somersault in any direction, you can ignore the navmesh 😁)
Building navmesh requires a complete view of the static world. The generated mesh is only correct when it accounts for all objects: interactions between objects affect the generated mesh in ways that are not easy (or fast) to reason about independently.
Intersecting objects can become obstructions to movement. Or they can form new surfaces that an agent can stand upon. You can’t really tell what it means to an agent until you mash it all together.
To do as little work as possible at runtime, we required *all* of the static objects to be loaded at one time to pre-build mesh for Sunset City.
We keep that pre-built navmesh loading during the game at all times. For the final version of the game (with both of the areas added via DLC) this required ~55MB memory.
We use Recast https://github.com/recastnavigation/recastnavigation to generate the triangle mesh, and (mostly for historical reasons) repack this into our own custom format.
Sunset Overdrive had two meshes: one for “normal” humanoid-sized bots (2m tall, 0.5m radius)

and one for “large” bots (4.5m tall, 1.35m radius)

Both meshes are generated as 16x16m tiles, and use a cell size of 0.125m when rasterizing collision geometry.
There were a few tools used in Sunset Overdrive to add some sense of dynamism to the static environment:
For pathfinding and bot-steering, we have runtime systems to control bot movement around dynamic obstacles.
For custom nav clues, we keep track of whether they are in use, to make it less likely that multiple bots are jumping over the same thing at the same time. This can help fan-out groups of bots, forcing them to take distinctly different paths.
Since Sunset Overdrive, we’ve added a dynamic obstruction system based on Detour https://github.com/recastnavigation/recastnavigation to temporarily cut holes in navmesh for larger impermanent obstacles like stopped cars or temporary structures.
We also have a way to mark-up areas of navmesh so that they can be toggled in a controlled fashion from script. It’s less flexible than the dyanamic obstruction system – but it is very fast: toggling flags for tris rather than retriangulation.
I spoke about Sunset Overdrive at the AI Summit a few years back – my slide deck is here:
Sunset City Express: Improving the NavMesh Pipeline in Sunset Overdrive
I can also highly recommend @AdamNoonchester‘s talk from GDC 2015:
AI in the Awesomepocalypse – Creating the Enemies of Sunset Overdrive
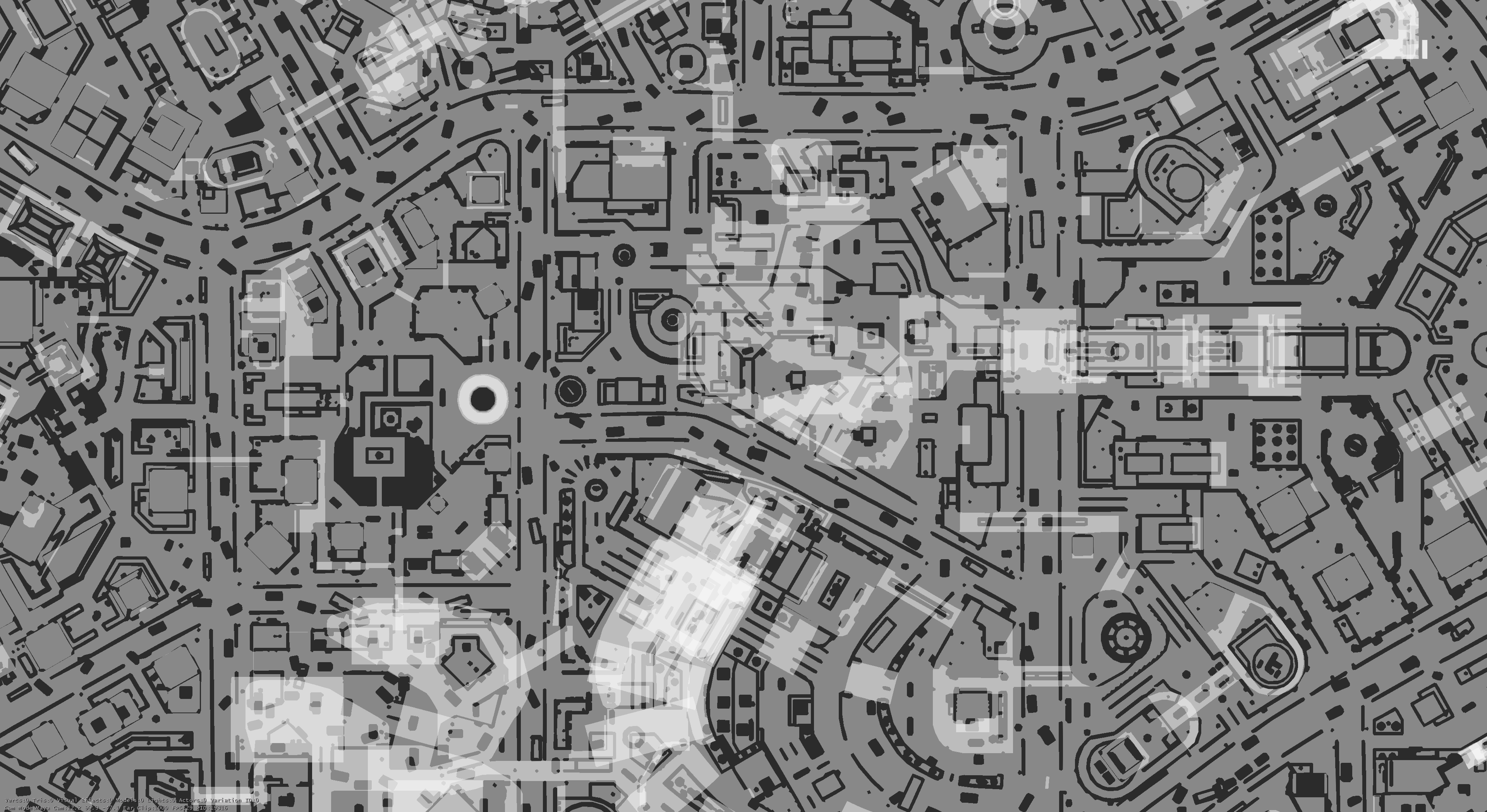
Here’s some navigation mesh, using the default in-engine debug draw (click for larger version)

What are we looking at? This is a top-down orthographic view of a location in the middle of Sunset City.
The different colors indicate different islands of navigation mesh – groups of triangles that are reachable from other islands via custom nav clues.
Bright sections are where sections of navmesh overlap in the X-Z plane.
There are multiple visualization modes for navmesh.
Usually, this is displayed over some in-game geometry – it exists to debug/understand the data in game and editor. Depending on what the world looks like, some colors are easier to read than others. (click for larger versions)




The second image shows the individual triangles – adjacent triangles do not reliably have different colors. And there is stable color selection as the camera moves, almost 😐
Also, if you squint, you can make out the 16x16m tile boundaries, so you can get a sense of scale.
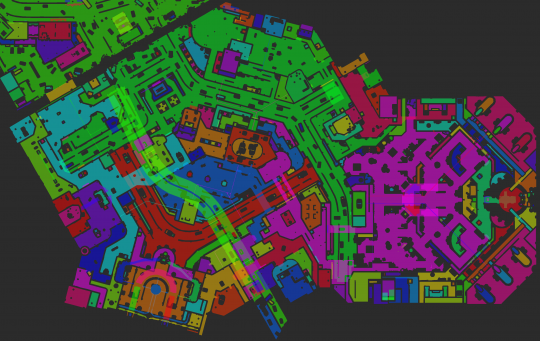
Here’s a map of the entirety of Sunset City:

“The Mystery of the Mooil Rig” DLC area:

“Dawn of the Rise of the Fallen Machine” DLC area:
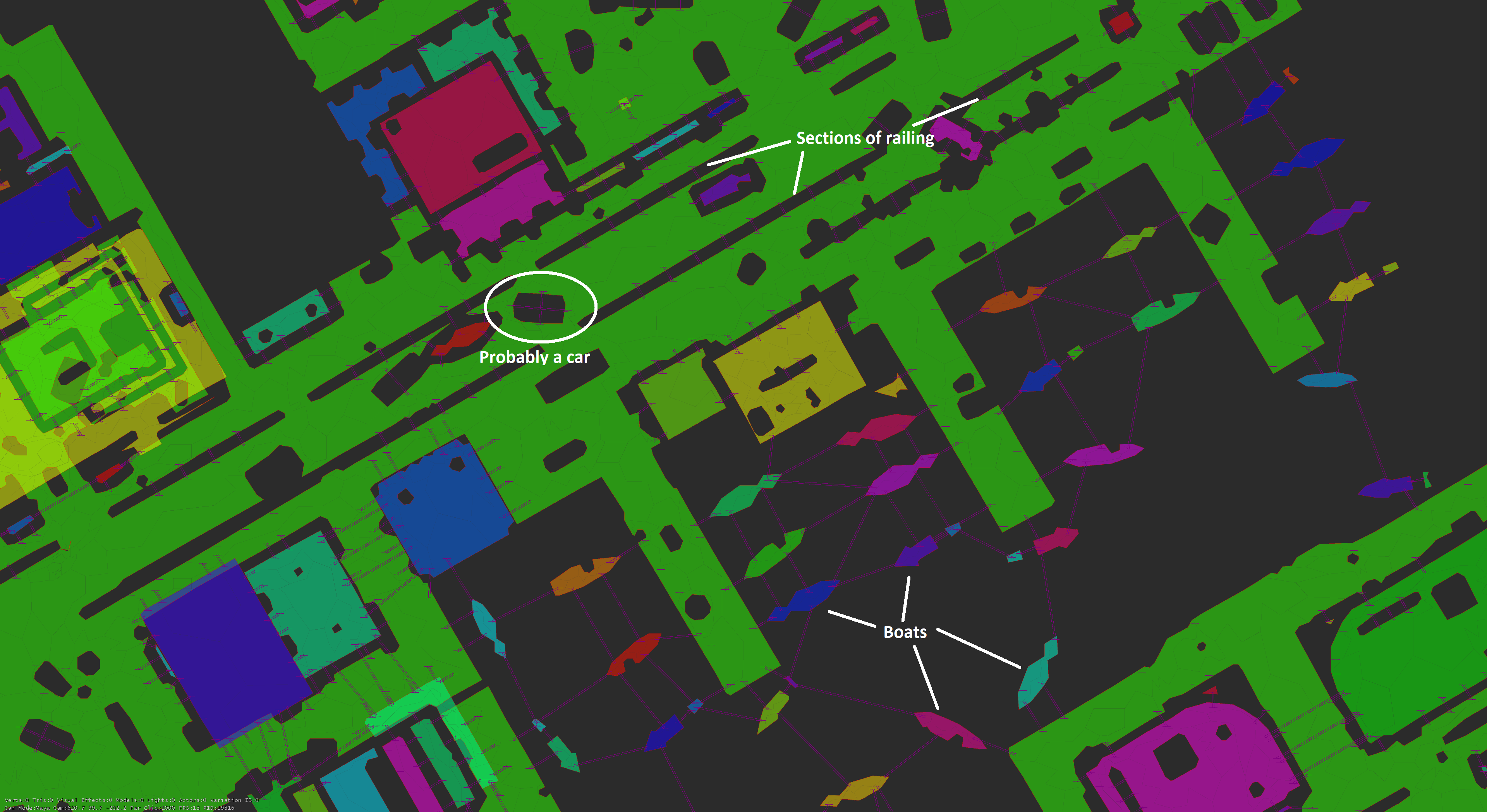
Referencing the comments from up-thread, these maps represent the places where agents can be. Additionally, there is connectivity information – we have visualization for that as well.
This image has a few extra in-engine annotations, and some that I added:
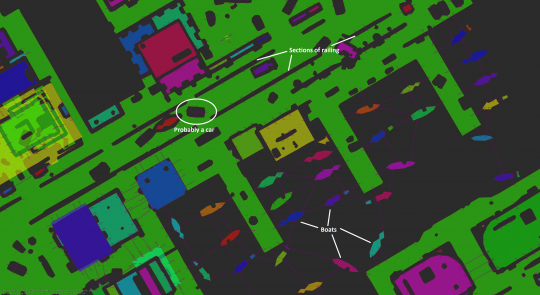
The purple lines represent custom nav clues – one line in each direction that is connected.
Also marked are some railings with clues placed at regular intervals, a car with clues crisscrossing it, and moored boats with clues that allow enemies to chase the player.
Also in this image are very faint lines on the mesh that show connectivity between triangles. When a bot is failing to navigate, it can be useful to visualize the connectivity that the mesh thinks it has :)
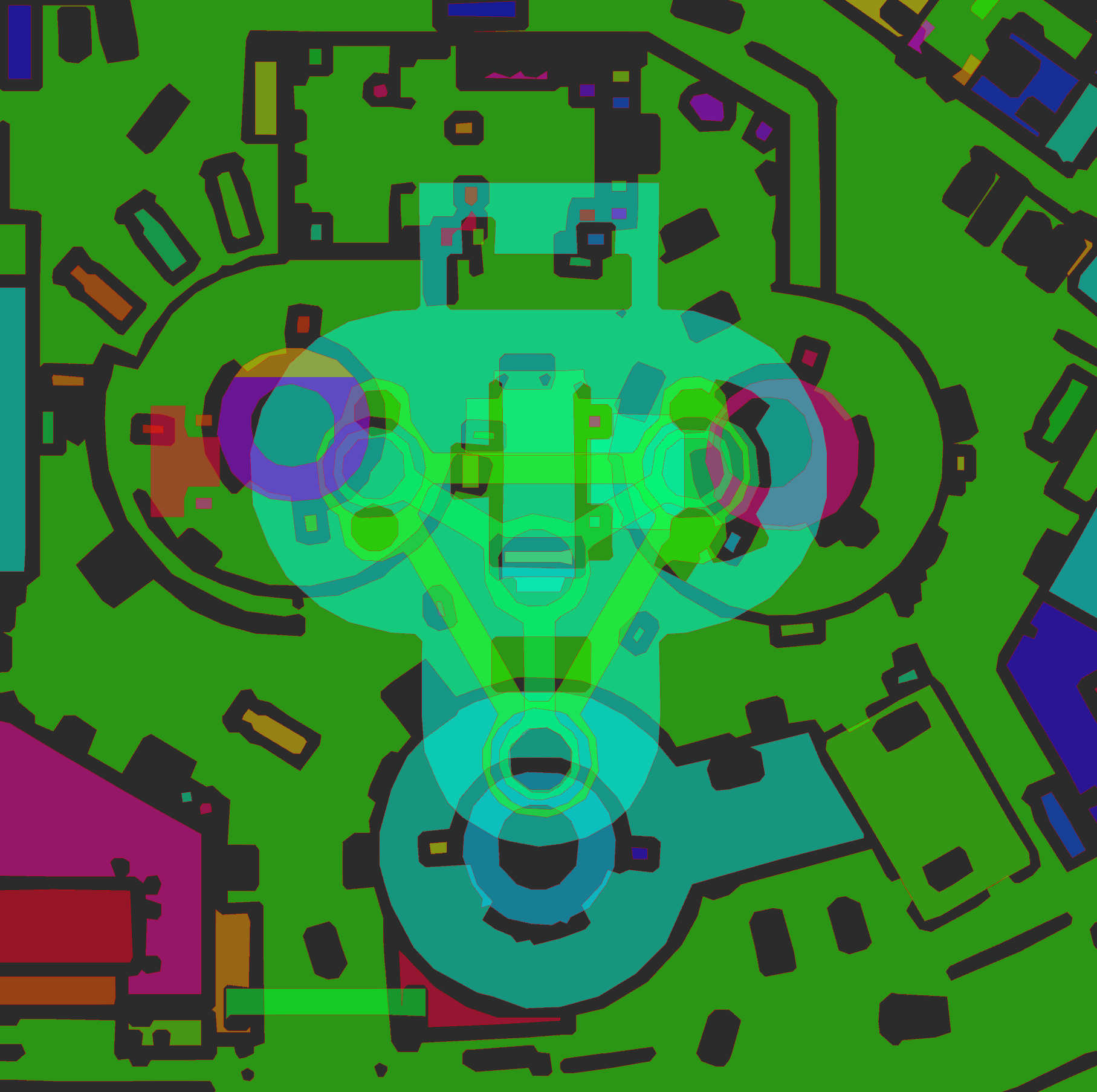
The radio tower where the fight with Fizzie takes place:
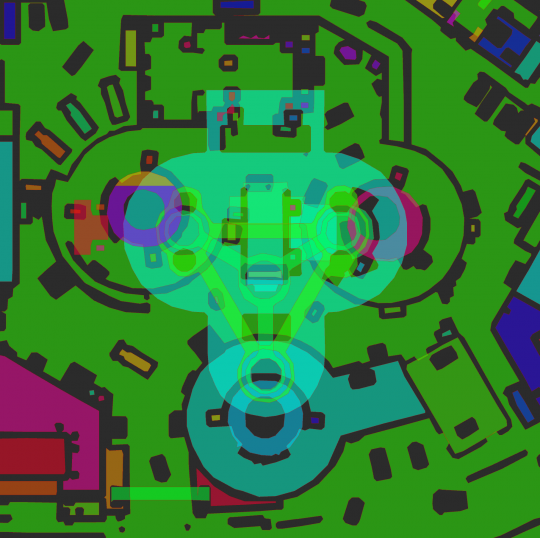

The roller coaster:


The roller coaster tracks are one single, continuous and complete island of navmesh.
Navigation mesh doesn’t line up neatly with collision geometry, or render geometry. To make it easier to see, we draw it offset +0.5m up in world-space, so that it’s likely to be above the geometry it has been generated for. (A while ago, I wrote a full-screen post effect that drew onto rendered geometry based on proximity to navmesh. I thought it was pretty cool, and it was nicely unambiguous & imho easier to read – but I never finished it, it bitrot, and I never got back to it alas.)
Since shipping Sunset Overdrive, we added support for keeping smaller pieces of navmesh in memory – they’re now loaded in 128x128m parts, along with the rest of the open world.
@despair‘s recent technical postmortem has a little more on how this works:
‘Marvel’s Spider-Man’: A Technical Postmortem
Even so, we still load it all of an open world region to build the navmesh: the asset pipeline doesn’t provide information that is needed to generate navmesh for sub-regions efficiently & correctly, so it’s all-or-nothing. (I have ideas on how to improve this. One day…)
Let me know if you have any questions – preferably via twitter @twoscomplement
This post was originally a twitter thread: